Semana 6 - Práctica Dirigida
Práctica Dirigida 4
FACULTAD DE CIENCIAS SOCIALES - PUCP
Curso: POL 278 - Estadística para el análisis político 1 | Semestre
2025 - 1
Dinámicas del uso de los medios de transporte en Lima
El crecimiento acelerado de Lima ha generado una creciente preocupación sobre la calidad y eficiencia de los medios de transporte en la ciudad. La congestión vehicular, la falta de infraestructura adecuada y los largos tiempos de viaje afectan diariamente a millones de limeños. En este contexto, el análisis de datos cuantitativos se vuelve indispensable para entender el comportamiento de los usuarios, identificar áreas críticas y diseñar soluciones efectivas. En ese sentido en esta sesión responderemos a la siguiente pregunta:
¿Cuál es el estado del transporte en Lima según sus residentes? 🤔
Para acercarnos a responder la pregunta antes planteada se buscó información relacionada al uso del transporte público en Lima. Por lo tanto se eligió la encuesta de Lima Como Vamos, la cual es realizada a ciudadanos de Lima y Callao con la finalidad de conocer su percepción acerca de la movilidad, ambiente, seguridad ciudadana, espacios de recreación, cultura y satisfacción con la ciudad. Pueden encontrar más información acerca de esta base aquí.
Para esta sesión se usará una versión subseteada de años anteriores que contiene las siguientes variables:
library(rio)
data=import("pd4_Limacomovamos.xlsx") ¿Cuál es el intervalo de confianza para la proporción de las personas que están satisfechas con el transporte público en Lima?
Para ello trabajaremos con la variable satis_transporte, que tiene dos valores posibles: Satisfecho y no satisfecho.
Para poder encontrar el intervalo de confianza para la proporción de ciudadanos de Lima y Callao satisfechos con el sistema de transporte, necesitamos tener muy claro la frecuencia de nuestro caso de éxito y del total de casos.
table(data$satis_transporte)##
## No satisfecho Satisfecho
## 3544 194sum(table(data$satis_transporte))## [1] 3738Hallamos el invervalo de confianza para una proporción con el comando
test_result <- prop.test(194, 3738, conf.level = 0.95)
test_result##
## 1-sample proportions test with continuity correction
##
## data: 194 out of 3738, null probability 0.5
## X-squared = 3000.5, df = 1, p-value < 2.2e-16
## alternative hypothesis: true p is not equal to 0.5
## 95 percent confidence interval:
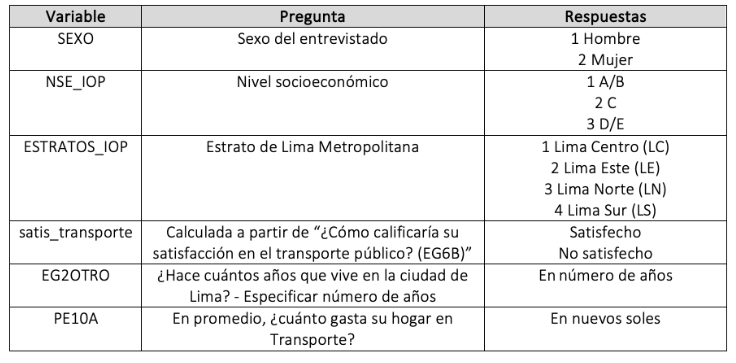
## 0.04511213 0.05962401
## sample estimates:
## p
## 0.05189941Pasos para graficar: Intervalo de Confianza de una proporción
# Extraer los resultados
proporcion <- test_result$estimate
lower_ci <- test_result$conf.int[1]
upper_ci <- test_result$conf.int[2]# Crear un data frame para ggplot
datita <- data.frame(
Categoria = "Proporción",
Proporción = proporcion,
Lower_CI = lower_ci,
Upper_CI = upper_ci
)Gráfico del Intervalo de Confianza de una proporción
# Graficar
library(ggplot2)
ggplot(datita, aes(x = Categoria, y = Proporción)) +
geom_bar(stat = "identity", fill = "lightblue") +
geom_errorbar(aes(ymin = Lower_CI, ymax = Upper_CI), width = 0.2, color = "darkblue") +
labs(title = "Intervalo de Confianza para Proporción",
y = "Proporción",
x = "") +
theme_minimal()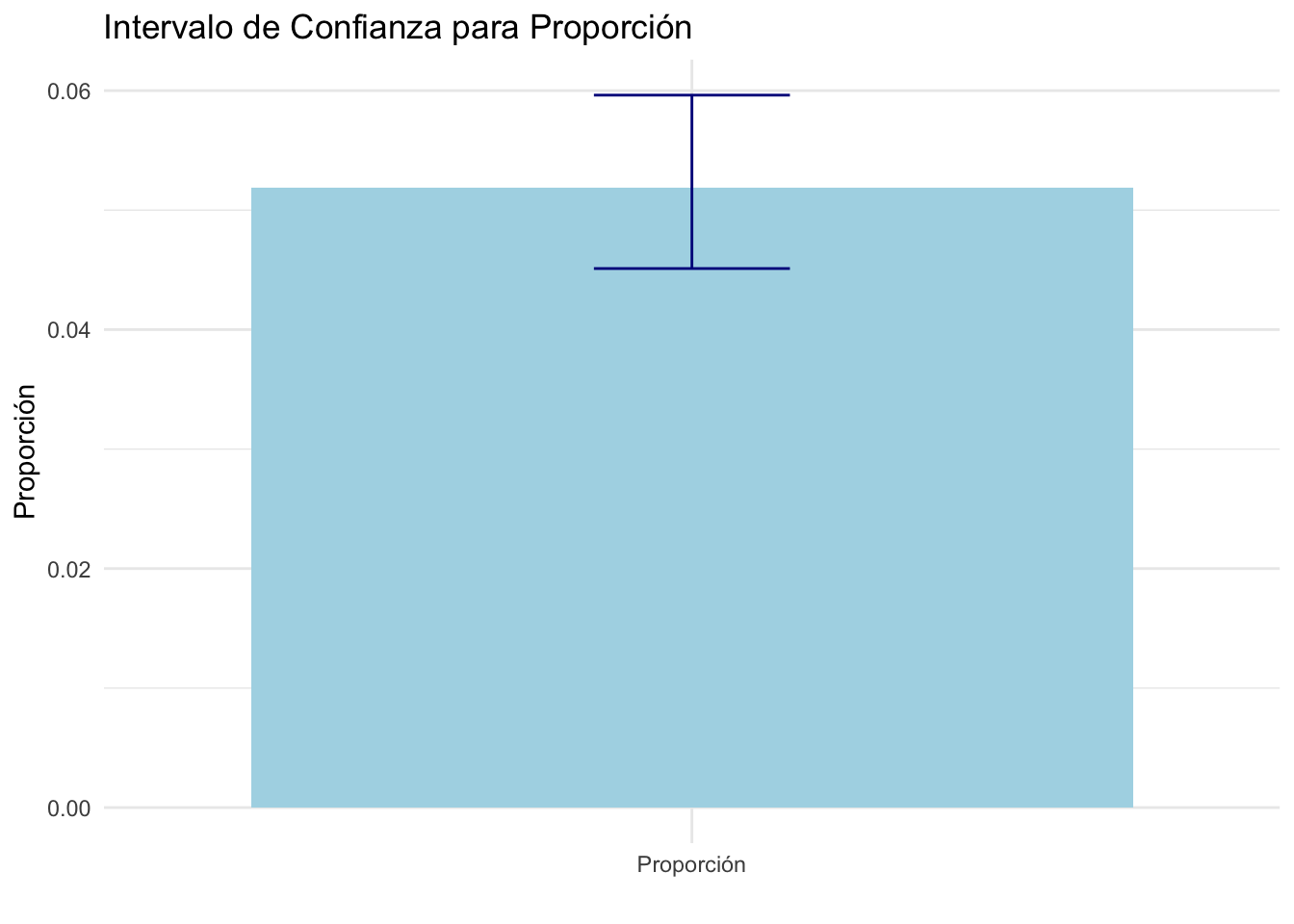
Esto quiere decir que tenemos un 95% de certeza de que, en la población, el porcentaje de ciudadanos de Lima y Callao satisfechos con el sistema de transporte oscila entre el 4.5% y 5.9% .
¿Cuánto gastan los residentes de Lima en transporte?
Hallemos el intervalo de confianza para la media de la variable “PE10A”.
El enunciado de la pregunta es indicar “En promedio, ¿cuánto gasta su hogar en Transporte?”.
class(data$PE10A) #Revisemos que nuestra variable esté bien clasificada## [1] "numeric"ciMean, del paquete lsr, es la función que calcula el intervalo de confianza de una media.
library(lsr)
ic_media = ciMean(data$PE10A, na.rm = TRUE) #con el último argumento indicamos no tomar en consideracion los valores perdidos (NA)
ic_media## 2.5% 97.5%
## [1,] 71.90169 90.764library(dplyr)
ic_grupo = data %>%
summarise(Media = mean(PE10A, na.rm=T),
LimiteInferior = ciMean(PE10A, na.rm=T)[1],
LimiteSuperior = ciMean(PE10A, na.rm=T)[2])
ic_grupo## Media LimiteInferior LimiteSuperior
## 1 81.33285 71.90169 90.764¿De qué manera la zona de Lima en la que vive la persona se relaciona con su gasto en transporte?
Hallemos el intervalo de confianza para el gasto en trasporte en promedio (PE10A) según estrato de lima (ESTRATOS_IOP).
Agreguemos etiquetas a la categórica

data = data %>%
mutate(ESTRATOS_IOP=factor(ESTRATOS_IOP, levels = (1:4), labels = c("Lima Centro","Lima Este","Lima Norte", "Lima Sur")))Crearemos una tabla con la media, máximo y mínimo de la variable PE10A, en base al grupo de ESTRATOS_IOP.
library(dplyr)
ic_grupo = data %>%
group_by(ESTRATOS_IOP)%>%summarise(Media = mean(PE10A, na.rm=T),
LimiteInferior = ciMean(PE10A, na.rm=T)[1],
LimiteSuperior = ciMean(PE10A, na.rm=T)[2])
ic_grupo## # A tibble: 4 × 4
## ESTRATOS_IOP Media LimiteInferior LimiteSuperior
## <fct> <dbl> <dbl> <dbl>
## 1 Lima Centro 114. 101. 128.
## 2 Lima Este 49.8 43.1 56.4
## 3 Lima Norte 95.0 65.0 125.
## 4 Lima Sur 61.2 54.0 68.4Según nuestra tabla, podemos afirmar que hay un 95% de probabilidad de que a nivel poblacional la media del grupo que los residentes de Lima Centro y Lima Norte gastan más en transporte que los de Lima Este.
Grafiquemos nuestros resultados.
library(ggplot2)
ggplot(ic_grupo, aes(x = ESTRATOS_IOP, y = Media)) +
geom_bar(stat = "identity", fill = "#00688B", color = "black") +
geom_errorbar(aes(ymin = LimiteInferior, ymax = LimiteSuperior), width = 0.2) +
# Etiquetas de la media
geom_text(aes(label = paste(round(Media, 2))), vjust = -1, size = 4) +
# Etiquetas de los valores mínimos
geom_text(aes(y = LimiteInferior, label = paste("min:", round(LimiteInferior, 2))),
vjust = 1.5, hjust = -0.2, size = 3, color = "white") +
# Etiquetas de los valores máximos
geom_text(aes(y = LimiteSuperior, label = paste("max:", round(LimiteSuperior, 2))),
vjust = -0.5, hjust = -0.2, size = 3, color = "#00688B") +
xlab("Zona de Lima") +
ylab("Promedio del gasto en transporte") +
ylim(0, 140) +
theme_minimal()
Con lo que muestra el gráfico, ¿cómo podemos complementar nuestra interpretación anterior?
- Lima Centro gasta significativamente más que Lima Este y Lima Sur, como lo indican los promedios y la falta de superposición considerable entre los IC.
- Lima Norte presenta un rango de gasto más amplio, lo que sugiere una variabilidad mayor en el gasto de transporte dentro de esa zona.
- Lima Este tiene un gasto más bajo y su intervalo de confianza no se superpone con el de Lima Centro, lo que podría indicar diferencias estadísticamente significativas entre estas dos zonas.
¿Existe una diferencia estadísticamente significativa entre el gasto en transporte entre hombres y mujeres?
Reviso mi df
str(data)## 'data.frame': 3744 obs. of 7 variables:
## $ SEXO : num 2 2 2 1 2 1 1 1 2 2 ...
## $ ESTRATOS_IOP : Factor w/ 4 levels "Lima Centro",..: 4 4 4 4 4 4 4 4 4 4 ...
## $ NSE_IOP : num 1 3 3 2 3 1 2 3 1 2 ...
## $ satis_transporte: chr "Satisfecho" "No satisfecho" "No satisfecho" "No satisfecho" ...
## $ EG2OTRO : num NA NA NA NA 2 NA 63 50 NA NA ...
## $ PE10A : num 50 10 8 10 10 10 5 5 15 90 ...
## $ Añoslima : chr NA NA NA NA ...GSexo = data %>%
group_by(SEXO) %>%
summarize(Media = mean(PE10A, na.rm = T))
GSexo## # A tibble: 2 × 2
## SEXO Media
## <dbl> <dbl>
## 1 1 87.1
## 2 2 76.0GSexo[1,2] - GSexo[2,2]## Media
## 1 11.0681La diferencia es de aprox 11 soles. ¿Puedo afirmar que existe esta diferencia en la población?
Para poder evaluar si existen o no diferencias poblacionales usaremos t.test
t.test(PE10A ~ SEXO, data = data)##
## Welch Two Sample t-test
##
## data: PE10A by SEXO
## t = 1.1169, df = 2160.1, p-value = 0.2642
## alternative hypothesis: true difference in means between group 1 and group 2 is not equal to 0
## 95 percent confidence interval:
## -8.365242 30.501440
## sample estimates:
## mean in group 1 mean in group 2
## 87.09212 76.02402El valor p- value es 0.2642, que es mayor que el nivel típico de significancia (generalmente α = 0.05). Un valor p alto sugiere que no hay suficiente evidencia para rechazar la hipótesis nula. En otras palabras, no podemos concluir que existe una diferencia significativa entre las medias de los dos grupos (hombres y mujeres) con respecto a la variable PE10A.
Ejercicios para casa
- Calcular el intervalo de confianza de la media para los años que llevan viviendo en Lima/Callao los residentes de Lima/Callao (EG2OTRO). Interprete
- Muestra un gráfico que los intervalos de confianza para la media de EG2OTRO según nivel socio económico (NSE_IOP). Interprete
- A partir de la variable EG2OTRO, se creó “Añoslima”. Que tiene dos grupos “Más de 50 años” o “De 50 años a menos”. Calcula el intervalo de confianza para la proporción de la variable “Añoslima” e interpreta.