Práctica Dirigida 9
FACULTAD DE CIENCIAS SOCIALES - PUCP
Curso: POL 278 - Estadística para el análisis político 1 | Semestre
2025 - 1
Regresión lineal múltiple
Hasta el momento, nos hemos encontrado en el campo del análisis bivariado. Sin embargo, en el mundo social, difícilmente se pueden explicar los fenómenos de interés con una sola variable. Incluso si nos interesa evaluar el efecto de un a variable en específico sobre un fenómeno de estudio, hay muchos otros factores que podrían influir en aquello que nos interesa explorar. Por ello, necesitamos recurrir al análisis multivariado y conocer el concepto de control estadístico.
El control estadístico nos permite aislar el efecto de otras variables. La idea es:
Evaluar si la asociación entre X e Y permanece si se remueve el efecto de otra variable, es decir, si se controla por una tercera variable.
Se analiza la relación entre X e Y para valores similares o iguales de una variable Z. De esta manera se elimina la influencia de Z en la relación entre X e Y. Lo anterior nos ayuda a acercarnos a una interpretación causar X -> Y.
Si la relación entre X e Y desaparece cuando se controla por Z, se dice que la relación era espúrea. En otras palabras, la relación dependendia de la influencia de Z y no de una conexión directa entre X e Y.
Aplicación práctica
Factores que determinan el acceso a la información en los Estados
El acceso a la información es fundamental para el funcionamiento de cualquier Estado democrático, ya que promueve la transparencia, la responsabilidad y la participación ciudadana.
Para poder realizar el análisis se han revisado las siguientes fuentes:
Digital Access Index El Índice de Acceso Digital es utilizado para medir y evaluar el nivel de acceso a las tecnologías digitales y a internet. Proporciona una medida de hasta qué punto las personas y las comunidades pueden utilizar y beneficiarse de las tecnologías digitales.
Egov-index El Índice de Gobierno Electrónico es una medida que evalúa el nivel de desarrollo y adopción de tecnologías de la información y la comunicación (TIC) en el sector público. Este índice se utiliza para medir la capacidad de los gobiernos para proporcionar servicios en línea, promover la participación ciudadana y utilizar las TIC de manera efectiva en la gestión gubernamental.
Democracy Index El Índice de Democracia es un índice que mide el estado de la democracia en países de todo el mundo. Es elaborado por The Economist (EIU) y evalúa el funcionamiento de los procesos e instituciones democráticas.
A partir de la información recolectada se ha creado una base de datos llamada Egov, la cual se compone de diversos índices. Vamos a utilizar los siguientes:
- accesoInformacion: índice de acceso a la información del país.
- participaciónDigital: índice de participación digital de la población del país.
- Servicios_Online: índice de calidad de servicios en línea del país.
- Capital Humano: índice de capital humano de la población del país.
- Telecommunicacion_Infraestructura: índice de infraestructura de las comunicaciones del país.
- ProcesoElectoral: índice de transparencia del proceso electoral.
- Policulture: índice de tolerancia a la pluralidad en un país.
- UsuariosInternet: porcentaje de población que utiliza internet en un país.
library(rio)
Egov=import("EGov.xlsx")
names(Egov)## [1] "pais" "participaciónDigital"
## [3] "Servicios_Online" "Capital_Humano"
## [5] "Telecommunicacion_Infrastructura" "ProcesoElectoral"
## [7] "Policulture" "accesoInformacion"
## [9] "UsuariosInternet"No olviden el análisis descriptivo antes de hacer los modelos.
Modelo 1
library(tidyverse)
modelo1 = lm(accesoInformacion ~participaciónDigital+Servicios_Online+Capital_Humano +Telecommunicacion_Infrastructura+ProcesoElectoral+ Policulture +UsuariosInternet ,data=Egov)
summary(modelo1)##
## Call:
## lm(formula = accesoInformacion ~ participaciónDigital + Servicios_Online +
## Capital_Humano + Telecommunicacion_Infrastructura + ProcesoElectoral +
## Policulture + UsuariosInternet, data = Egov)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.204651 -0.033054 0.002505 0.032268 0.116256
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.1208398 0.0263792 -4.581 1.13e-05 ***
## participaciónDigital -0.0788712 0.0914304 -0.863 0.39004
## Servicios_Online 0.0809775 0.0948445 0.854 0.39491
## Capital_Humano 0.2968634 0.0555961 5.340 4.43e-07 ***
## Telecommunicacion_Infrastructura 0.3561180 0.0782623 4.550 1.28e-05 ***
## ProcesoElectoral 0.0075843 0.0019182 3.954 0.00013 ***
## Policulture 0.0139957 0.0043417 3.224 0.00163 **
## UsuariosInternet 0.0015629 0.0006815 2.293 0.02355 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.06194 on 121 degrees of freedom
## Multiple R-squared: 0.926, Adjusted R-squared: 0.9217
## F-statistic: 216.3 on 7 and 121 DF, p-value: < 2.2e-16Interpretamos
¿El modelo es válido?
Establezcamos nuestras hipótesis:
- H0: El modelo de regresión no es válido
- H1: El modelo de regresión es válido (las variables independientes aportan al modelo)
Luego nos fijamos en el p-value Como el p valor es < 2.2e-16 entonces podemos afirmar que hay suficiente evidencia para rechazar la H0, por lo que concluimos que el modelo es válido como modelo de predicción.
¿Qué tanto explica el modelo?
Observamos el R2 ajustado.
Analizar cuánto de la variabilidad de la variable dependiente (y) es explicada por las variables independientes elegidas, para ello revisamos el R2 (Adjusted R-squared, por ser un modelo lineal múltiple).
En nuestro modelo, este arrojó el valor de 0.9217, por lo que podemos concluir que el modelo explica aproximadamente el 92.2% (0.9217*100) de la variabilidad en el acceso a la información (variable dependiente). En otras palabras, este valor alto de R cuadrado ajustado indica que el modelo se ajusta muy bien a los datos y hace un buen trabajo al explicar la relación entre las variables independientes y la variable dependiente. Sin embargo, el valor del R cuadrado ajustado no te dice nada sobre la significancia estadística de las variables individuales, ni sobre la causalidad. Por ello analizaremos también las variables de forma independiente en el siguiente paso.
Recordemos que el R cuadrado puede tomar valores entre 0 y 1. Un R cuadrado de 1 indica que el modelo explica toda la variabilidad de la variable Y. Un R cuadrado de 0 indica que el modelo no explica nada de la variabilidad de la variable Y.
¿Las variables aportan al modelo?
Revisamos p-value por cada variable independiente.
- Esperamos obtener un p-value <0.05.
- Nos damos cuenta que no todas las variables independientes tienen un p-value <0.05, es el caso de: participaciónDigital y Servicios_Online
¿Cuáles son los coeficientes de la ecuación?
Podemos obtener extraer los coeficientes del modelo:
No olvidar identificar el signo de cada coeficiente, este tendrá repercusión en la ecuación y su futura aplicación
modelo1$coefficients## (Intercept) participaciónDigital
## -0.120839771 -0.078871158
## Servicios_Online Capital_Humano
## 0.080977535 0.296863439
## Telecommunicacion_Infrastructura ProcesoElectoral
## 0.356118022 0.007584279
## Policulture UsuariosInternet
## 0.013995704 0.001562898De esa manera puedo hallar la ecuación:
\[ Y = -0.12 + \text{participaciónDigital} \times (-0.078) + \text{Servicios\_Online} \times (0.080) + \text{Capital\_Humano} \times (0.29) + \text{Telecommunicacion\_Infrastructura} \times (0.35) + \text{ProcesoElectoral} \times (0.0075) + \text{Policulture} \times (0.013) + \text{UsuariosInternet} \times (0.0015) \]
Es decir, se tienen las siguientes relaciones entre VD y las VI:
Por cada unidad adicional de puntaje en participación digital, el índice de acceso a la información disminuye en 0.078 puntos (relación inversa).
Por cada unidad adicional de puntaje de servicios online, el índice de acceso a la información aumenta en 0.08 puntos. (relación directa).
Por cada unidad adicional de puntaje en Capital Humano, el índice de acceso a la información aumenta en 0.08 puntos (relación directa).
Por cada unidad adicional de puntaje de telecomunicaciones e infraestructura, el índice de acceso a la información aumenta en 0.35 puntos. (relación directa).
Por cada unidad adicional de puntaje de Procesos Electorales, el índice de acceso a la información aumenta en 0.0075 puntos. (relación directa).
Por cada unidad adicional de puntaje de Cultura política, el índice de acceso a la información aumenta en 0.013 puntos. (relación directa).
Por cada unidad adicional de puntaje de acceso de Usuarios a Internet, el índice de acceso a la información aumenta en 0.0015 puntos. (relación directa).
OJO: La ecuación de la recta debe incluir TODAS las variables analizadas, tengan o no una influencia significativa en la VD.
¿Qué sucede si retiro las variables independientes que no aportan al modelo 1? Veamos un segundo modelo 👀 .
Modelo 2
library(dplyr)
library(ggplot2)
modelo2 = lm(accesoInformacion ~Capital_Humano +Telecommunicacion_Infrastructura+ProcesoElectoral+ Policulture +UsuariosInternet ,data=Egov)
summary(modelo2)##
## Call:
## lm(formula = accesoInformacion ~ Capital_Humano + Telecommunicacion_Infrastructura +
## ProcesoElectoral + Policulture + UsuariosInternet, data = Egov)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.205352 -0.037077 0.002991 0.035621 0.111936
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.1220640 0.0262044 -4.658 8.15e-06 ***
## Capital_Humano 0.2884448 0.0538523 5.356 4.02e-07 ***
## Telecommunicacion_Infrastructura 0.3513669 0.0774659 4.536 1.34e-05 ***
## ProcesoElectoral 0.0075854 0.0018682 4.060 8.66e-05 ***
## Policulture 0.0145801 0.0042686 3.416 0.000863 ***
## UsuariosInternet 0.0016876 0.0006405 2.635 0.009498 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.06163 on 123 degrees of freedom
## Multiple R-squared: 0.9255, Adjusted R-squared: 0.9225
## F-statistic: 305.8 on 5 and 123 DF, p-value: < 2.2e-16Interpretamos
¿El modelo es válido?
Establezcamos nuestras hipótesis:
- H0: El modelo de regresión no es válido
- H1: El modelo de regresión es válido (las variables independientes aportan al modelo)
Luego nos fijamos en el p-value Como el p valor es < 2.2e-16 entonces podemos afirmar que hay suficiente evidencia para rechazar la H0, por lo que concluimos que el modelo sí es válido como modelo de predicción.
¿Qué tanto explica el modelo?
Observamos el R2 ajustado.
Analizar cuánto de la variabilidad de la variable dependiente (y) es explicada por las variables independientes elegidas, para ello revisamos el R2 (Adjusted R-squared).
En nuestro modelo, este arrojó el valor de 0.9225, por lo que podemos concluir mi modelo explica aproximadamente el 92.25% (0.9225*100) de la variabilidad en el acceso a la información (variable dependiente). E
¿Las variables aportan al modelo?
Revisamos p-value por cada variable independiente.
- Esperamos obtener un p-value <0.05.
- Todas las variables independientes aportan al modelo.
¿Cuáles son los coeficientes de la ecuación?
modelo2$coefficients## (Intercept) Capital_Humano
## -0.122063970 0.288444800
## Telecommunicacion_Infrastructura ProcesoElectoral
## 0.351366905 0.007585449
## Policulture UsuariosInternet
## 0.014580126 0.001687594De esa manera puedo hallar la ecuación:
\[ Y = -0.12 + \text{Capital\_Humano} \times (0.288) + \text{Telecommunicacion\_Infrastructura} \times (0.35) + \text{ProcesoElectoral} \times (0.00758) + \text{Policulture} \times (0.0145) + \text{UsuariosInternet} \times (0.0016) \] En este modelo, las variables se interpretan de la siguiente manera:
Por cada unidad adicional de puntaje en Capital Humano, el índice de acceso a la información aumenta en 0.288 puntos (relación directa).
Por cada unidad adicional de puntaje de telecomunicaciones e infraestructura, el índice de acceso a la información aumenta en 0.35 puntos. (relación directa).
Por cada unidad adicional de puntaje de Procesos Electorales, el índice de acceso a la información aumenta en 0.00758 puntos. (relación directa).
Por cada unidad adicional de puntaje de Cultura política, el índice de acceso a la información aumenta en 0.0145 puntos. (relación directa).
Por cada unidad adicional de puntaje de acceso de Usuarios a Internet, el índice de acceso a la información aumenta en 0.0016 puntos. (relación directa).
¿Mi modelo ha mejorado?
Ligeramente, mientras que el modelo 1 explicaba un 92.17% y el modelo 2 92.25%. A pesar de que mi modelo 1 tiene un rango de explicación alto, con el modelo 2 se ha podido demostrar que el modelo puede mejorar (así la mejora no ha haya sido sustancial).
También es importante notar que los coeficientes estimados de las VI han cambiado.
Predicción
¿Cuál sería el índice de acceso a la información si reemplazamos el puntaje de cada variable independiente con su respectivo promedio?
Egov %>%
summarise(mean(Capital_Humano, na.rm=T), mean(Telecommunicacion_Infrastructura, na.rm=T),
mean(ProcesoElectoral, na.rm=T), mean(Policulture, na.rm=T), mean(UsuariosInternet, na.rm=T))## mean(Capital_Humano, na.rm = T) mean(Telecommunicacion_Infrastructura, na.rm = T)
## 1 0.6419609 0.3801159
## mean(ProcesoElectoral, na.rm = T) mean(Policulture, na.rm = T)
## 1 6.167907 5.734264
## mean(UsuariosInternet, na.rm = T)
## 1 49.65271Y = -0.12 + 0.29(0.64) + 0.35(0.38) + 0.01 (6.17) + 0.01 (5.73) + 0.002(49.65)
Y = -0.12 + 0.186 + 0.133 + 0.062 + 0.057 + 0.099
Y = 0.417
predict(modelo2, data.frame(Capital_Humano = 0.64, Telecommunicacion_Infrastructura = 0.38, ProcesoElectoral = 6.17, Policulture = 5.73, UsuariosInternet = 49.65))## 1
## 0.4101955En conclusión, para valores promedio de las variables independientes, el índice de acceso a la información es de 0.41 puntos.
¿Qué pasa si queremos predecir el índice de acceso a la información para diferentes valores de una variable independiente?
En este caso, se puede reemplazar dejando las otras variables en el promedio. Por ejemplo, se quiere calcular el índice de acceso a la información para diferentes valores de la telecomunicación e infraestuctura. Lo primero es calcular los valores a reemplazar. En este caso usaremos el mínimo, la mediana y el máximo.
Egov %>%
summarise(min(Telecommunicacion_Infrastructura, na.rm=T),
median(Telecommunicacion_Infrastructura, na.rm=T), max(Telecommunicacion_Infrastructura, na.rm=T))## min(Telecommunicacion_Infrastructura, na.rm = T)
## 1 0
## median(Telecommunicacion_Infrastructura, na.rm = T)
## 1 0.34584
## max(Telecommunicacion_Infrastructura, na.rm = T)
## 1 0.84141Luego, podemos reemplazar estos diferentes valores de telecomunicaciones e infraestructura, dejando las otras dos variables constantes en el promedio.
Usando el mínimo:
predict(modelo2, data.frame(Capital_Humano = 0.64, Telecommunicacion_Infrastructura = 0, ProcesoElectoral = 6.17, Policulture = 5.73, UsuariosInternet = 49.65))## 1
## 0.2766761Usando la mediana:
predict(modelo2, data.frame(Capital_Humano = 0.64, Telecommunicacion_Infrastructura = 0.35, ProcesoElectoral = 6.17, Policulture = 5.73, UsuariosInternet = 49.65))## 1
## 0.3996545Usando el máximo:
predict(modelo2, data.frame(Capital_Humano = 0.64, Telecommunicacion_Infrastructura = 0.84, ProcesoElectoral = 6.17, Policulture = 5.73, UsuariosInternet = 49.65))## 1
## 0.5718243¿Qué variable aporta más?
Para interpretar cómo cada variable independiente contribuye a la variabilidad de la variable dependiente (accesoInformacion), podemos usar los coeficientes estandarizados. Estos coeficientes nos ayudan a comparar, en una misma escala, el impacto que tiene cada variable independiente sobre la variable dependiente, permitiéndonos identificar cuáles tienen un efecto más fuerte.
IMPORTANTE: Los coeficientes estandarizados solo sirven para evaluar y analizar qué variable aporta más. La ecuación de la recta se debe realizar con los coeficientes estimados.
library(jtools)
summ(modelo2, scale=T)| Observations | 129 |
| Dependent variable | accesoInformacion |
| Type | OLS linear regression |
| F(5,123) | 305.76 |
| R² | 0.93 |
| Adj. R² | 0.92 |
| Est. | S.E. | t val. | p | |
|---|---|---|---|---|
| (Intercept) | 0.41 | 0.01 | 75.72 | 0.00 |
| Capital_Humano | 0.06 | 0.01 | 5.36 | 0.00 |
| Telecommunicacion_Infrastructura | 0.08 | 0.02 | 4.54 | 0.00 |
| ProcesoElectoral | 0.03 | 0.01 | 4.06 | 0.00 |
| Policulture | 0.02 | 0.01 | 3.42 | 0.00 |
| UsuariosInternet | 0.05 | 0.02 | 2.63 | 0.01 |
| Standard errors: OLS; Continuous predictors are mean-centered and scaled by 1 s.d. The outcome variable remains in its original units. |
Los resultados anteriores nos demuestran que las variables con mayor impacto son Telecommunicacion_Infrastructura (0.08) y Capital_Humano (0.06)
plot_summs(modelo2, scale = T)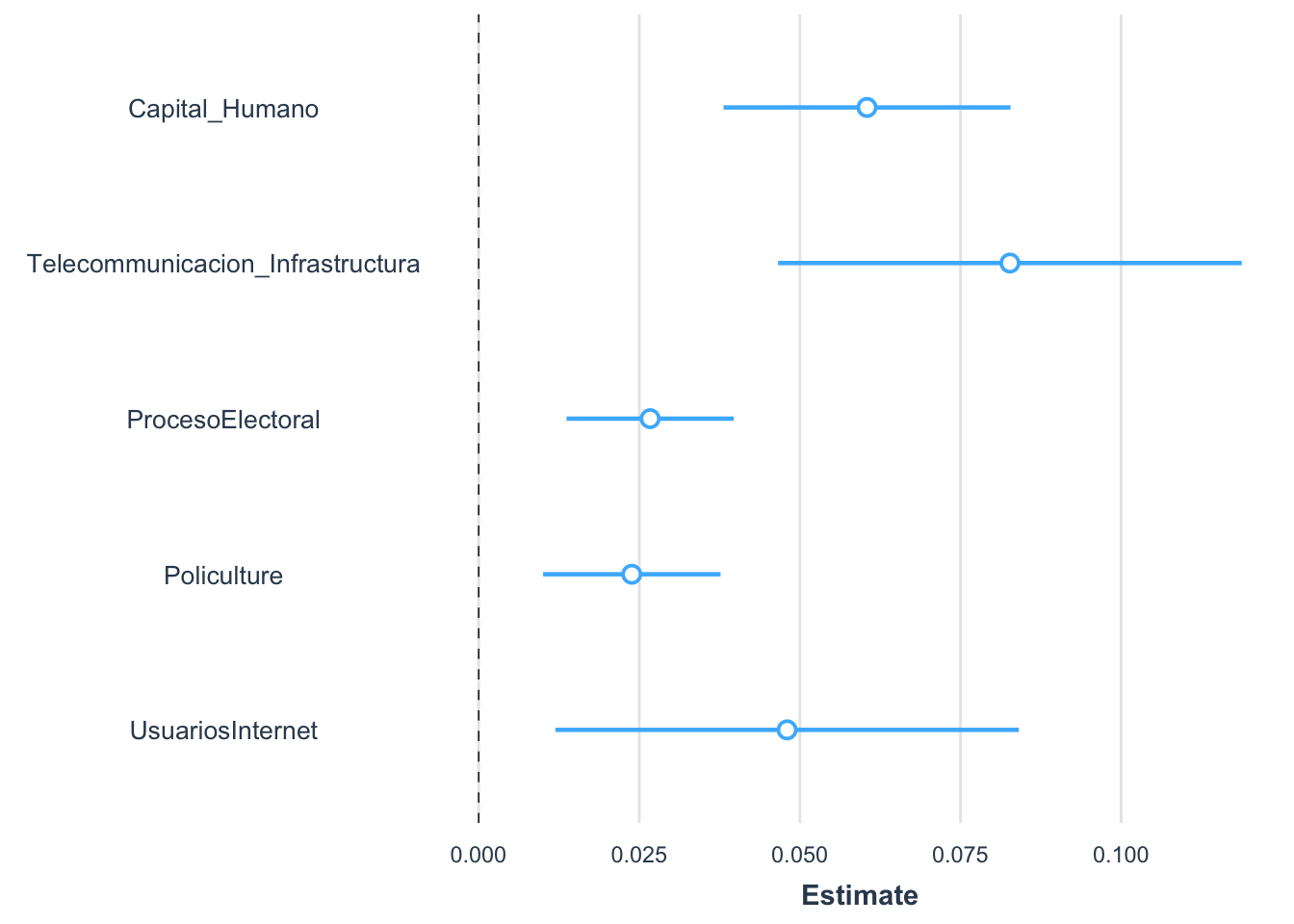
Ejercicio para clase
Utiliza la base fsi_democracy.xlsx y crea un modelo de regresión múltiple para analizar el impacto de las distintas variables en la Fragilidad del Estado (Total).
En este caso, las variables independientes que usaremos para predecir la Fragilidad del Estado serán: Aparato_seguridad Economia Servicios_publicos Intervencion_externa
Predice la Fragilidad de un Estado que usando valores significativos para cada variable independiente.